CALLip: Lipreading using Contrastive and Attribute Learning
Abstract
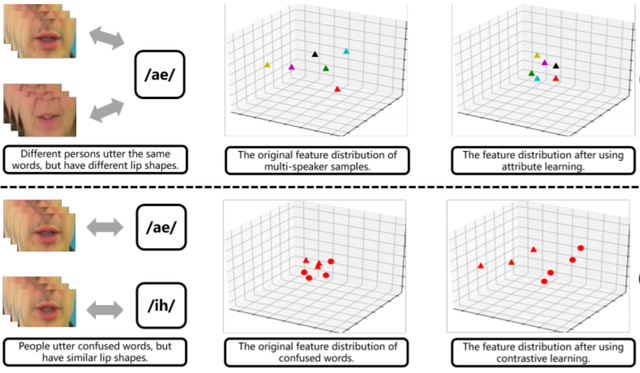
Lipreading, aiming at interpreting speech by watching the lip movements of the speaker, has great significance in human communication and speech understanding. Although has reached a feasible performance, lipreading still faces two crucial challenges: 1) the considerable lip movement variations cross different persons when they utter the same words; 2) the similar lip movements of people when they utter some confused phonemes. To tackle these two problems, we propose a novel lipreading framework, CALLip, which employs attribute learning and contrastive learning. The attribute learning extracts the speaker identity-aware features through a speaker recognition branch, which are able to normalize the lip shapes to eliminate cross-speaker variations. Considering that audio signals are intrinsically more distinguishable than visual signals, the contrastive learning is devised between visual and audio signals to enhance the discrimination of visual features and alleviant the viseme confusion problem. Experimental results show that CALLip does learn a better features of lip movements. The comparisons on both English and Chinese benchmark datasets, GRID and CMLR, demonstrate that CALLip outperforms six state-of-the-art lipreading methods without using any additional data.